Training AI to Identify Animals in the Wild


Click here for GitHub Repo.
Yet another image classification model, except this time I've tackled the Ohio Small Animals dataset, available at LILA BC: Labeled Information Library of Alexandria: Biology and Conservation
The dataset contains over 118,000 images, taken from camera traps scattered around Ohio.
These images are generally taken by camera traps in order to monitor the activity level and diversity of various species in the area, such as squirrels, foxes, raccoons, etc. As a result, you'll be able to see several amazing pictures captured around Ohio, such as this one!
 Image Source: OHPARC.org
Image Source: OHPARC.org
After handling the image preprocessing (which you can find along with the entire model's .ipynb file in the GitHub link), I then constructed the model with the parameters found in the code snippet below.
This structure was chosen after several previous iterations fell short of the performance I was looking for. In the order they appear...
Rescaling: Normalizes the data, in which each pixel's (color) value in the image is divided by 255 (since each entry in an RGB, or Red Green Blue, value ranges from 0 to 254) and makes it such that the low and high end of these values become 0 and 1, respectively.
Conv2D: Applies a filter that surveys the image in order to extract certain "features", which is at the core of how convolutional neural networks actually learn to distinguish objects from eachother.
MaxPooling2D: In a sense, MaxPooling2D is responsible for taking the output from the Conv2D layer from before, extracting its most prominent or pronounced features (or the most 'important' features it's found), keeps those, and discards the rest. This is a safe and reliable way to downscale the heftyness of large pools of data, such as a large dataset of high-resolution images.
Flatten: Right before the model actually predicts what it's looking at, the Flatten layer takes all previously gathered data and flattens it into a 1-dimensional array of data in which the predictive layers can correctly read from. This is a way to manipulate how the data is being read by the model, and ensures everything is in the correct format.
Dense: Finally, the dense layers are what actually do the predicting. It takes all the features found from previous layers and, given a certain number of nodes, will take an input and send its output to a subsequent node that's most compatible with the input's features.
You'll see at the end of the model's declaration two different Dense layers, with one having 128 nodes, and the next having num_classes amount of nodes (which would be equal to the number of unique animals we're trying to classify, so around 48.)
Each node in the final Dense layer belongs to one of the 48 different animal categories, and thus when an input image is run through the model the node with the highest output value determines what label to give the input image.
Code Snippet Showing Model Construction
model = tf.keras.Sequential([
tf.keras.layers.Rescaling(1./255),
tf.keras.layers.Conv2D(64, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Conv2D(64, 3, activation='relu'),
tf.keras.layers.MaxPooling2D(),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dense(num_classes)
])
model.compile(
optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy']
)
history = model.fit(
train_ds,
validation_data = val_ds,
epochs = 10
)
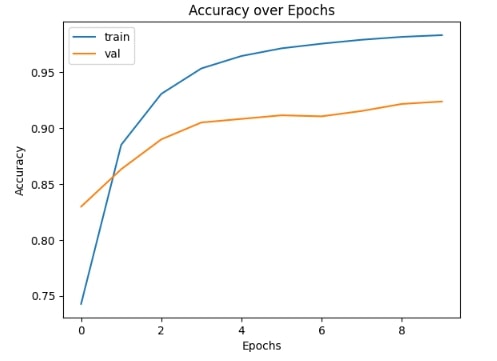
And, in order to provide an actual demonstration of the model's performance, below I've assigned it the task of trying to identify what animals reside in each of 9 random images.
Above each image, the top-most label is what the model predicts is in the image, and the bottom-most label is what the image actually contains.
You'll see that it was actually able to correctly identify each and every creature in the images!

Awesome!
This project was a great learning experience in that I was solely responsible for every aspect of this project: parsing of the dataset, image preprocessing, model creation, hyperparameter tuning, and data visualization.
And hopefully, this post may provide something valuable to anyone interested in starting their own machine learning journey.
Cheers!
- Stuart
Balasubramaniam S. Optimized Classification in Camera Trap Images: An Approach with Smart Camera Traps, Machine Learning, and Human Inference. Master’s thesis, The Ohio State University. 2024.